
Introduzione di Gian Luigi Nicolosi
La maggior parte delle applicazioni attuali di AI rientrano nel concetto di
intelligenza artificiale “ristretta” (“narrow”, “weak”) che esegue un singolo
compito o una serie di attività strettamente correlate. Questi sistemi sono
potenti, ma l’ambito d’azione è limitato: essi tendono infatti a concentrarsi
sulla creazione di efficienza.
Quale futuro per l’Intelligenza Artificiale?
Apriamo un dibattito…
Le maggiori difficoltà od ostacoli che devono venir superati per
raggiungere applicazioni di AI da considerarsi affidabili, riguardano gli
investimenti, l’ampiezza, la diversificazione e i bias di selezione dei dati
che devono servire come input e training dei sistemi di AI, rischi etici,
conflitti di interesse fra sviluppatori di AI, la trasparenza delle procedure
(superando il “black box”), la certificazione come prodotto medico, la
segnalazione e la gestione degli errori e la diffidenza degli operatori.
Per inviare il vostro contributo al forum, inviate un’email a cardiologianegliospedali@anmco.it
Le nuove frontiere del NLP per l’analisi dei referti: a che punto siamo?
Potenzialità e limiti dell’elaborazione del linguaggio naturale in Cardiologia molecolare per l’estrazione di informazione clinica
Introduzione
La digitalizzazione dei processi clinicoassistenziali richiede alle strutture sanitarie di gestire un numero sempre crescente di testi informatizzati: referti, note infermieristiche e lettere di dimissione sono solo alcuni degli esempi più comuni. Nella nuova sanità digitale, l’abbondanza di queste informazioni può essere sfruttata grazie alle tecniche di Elaborazione del Linguaggio Naturale (NLP), branca dell’Intelligenza Artificiale (AI) che grazie all’analisi automatica dei testi può facilitare il recupero di informazioni e dati da parte del personale clinico/assistenziale e dei ricercatori. I documenti medico-clinici sono infatti ricchi di informazioni rilevanti, ma difficili da inserire in database e registri se non mediante un tedioso lavoro manuale: raffinare questi “diamanti grezzi” in modo automatico consentirebbe dunque un notevole risparmio di tempo e una considerevole “economia di scala” per un migliore impiego dei dati raccolti. Per comprendere meglio limiti e potenzialità di queste strategie, in collaborazione con il laboratorio di Cardiologia Molecolare di ICSM Maugeri e con il BMI Lab “Mario Stefanelli” dell’Università di Pavia abbiamo implementato un processo automatizzato per l’estrazione di informazione dai referti cardiologici, basandoci su modelli considerati oggi lo stato dell’arte, come BERT [Delvin et al., 2019], appartenente ad una famiglia di nuove reti neurali chiamate “transformers” che, grazie alle loro particolari caratteristiche, hanno portato ad un rapido progresso del settore negli ultimi anni.
Identificare Eventi Clinici con BERT
Partendo da un lavoro precedentemente pubblicato dal nostro gruppo [Viani et al., 2019], abbiamo affrontato il problema dell’identificazione automatica nei referti della Unità Operativa della Cardiologia Molecolare (ICS Maugeri Pavia) di eventi clinici appartenenti a quattro differenti categorie: problema, test, trattamento e occorrenza. L’analisi è stata condotta su 75 referti medici in lingua italiana, utilizzando il solo sistema BERT. Il problema è stato formulato come un task di apprendimento supervisionato in cui gli eventi di interesse, divisi in categorie, sono evidenziati nel testo (annotati) da un esperto (annotatore). I risultati ottenuti mostrano performance sistematicamente superiori al 90% in termini di sensitività e specificità, nonostante questo nuovo approccio non includa alcuna codifica della conoscenza medica. Proprio l’assenza di regole rigide e dizionari sviluppati ad hoc conferisce al modello anche la capacità di tollerare errori di battitura ed abbreviazioni. L’esperimento ha dunque evidenziato non solo una buona accuratezza del modello, ma anche flessibilità e ottima capacità di generalizzazione, ottenute peraltro a partire da un dataset molto piccolo. Un esempio di referto annotato automaticamente è mostrato in Figura 1.

Pre-Training e Transfer Learning
Ma come si ottengono prestazioni così buone a partire da così pochi dati? Prima di essere calibrato per uno scopo specifico come l’analisi di un referto di Cardiologia (finetuning), il modello affronta un allenamento preliminare a partire da raccolte di testo molto ampie ma meno specializzate (e.g., Wikipedia) che gli consentono di imparare relazioni generali in campo lessicale, semantico e grammaticale tipiche della lingua utilizzata (pre-training). L’apprendimento non parte quindi da zero, ma avviene tramite trasferimento della conoscenza (transfer learning) sulla lingua con cui sono scritti i referti. Il modello si potrà quindi concentrare successivamente sull’apprendimento dei pattern peculiari del dominio clinico di interesse.
Estrarre Informazioni con approcci di Question-Answering
Il problema dell’estrazione di informazione dai referti è stato inizialmente limitato alla classificazione di porzioni di testo (e.g., “Posta diagnosi di sindrome del QT Lungo (LQTS), è stata intrapresa terapia betabloccante.”) in categorie associate a concetti di diversa natura (e.g., “LQTS” = problema, “terapia betabloccante” = trattamento). Il passo successivo riguarda il riempimento automatico di campi in un database, come ad esempio un registro di patologia. A questo scopo è conveniente riconfigurare il problema sotto forma di Question- Answering (QA): per ogni campo da compilare, si formula quindi una domanda (e.g., “quanto vale la frequenza cardiaca media riportata dall’ECG?”) e si annota nel testo la risposta corrispondente (e.g., “80 bpm”), definendo quindi le relazioni attributo-valore tramite coppie domanda-risposta, come mostrato dalla pipeline in Figura 2.
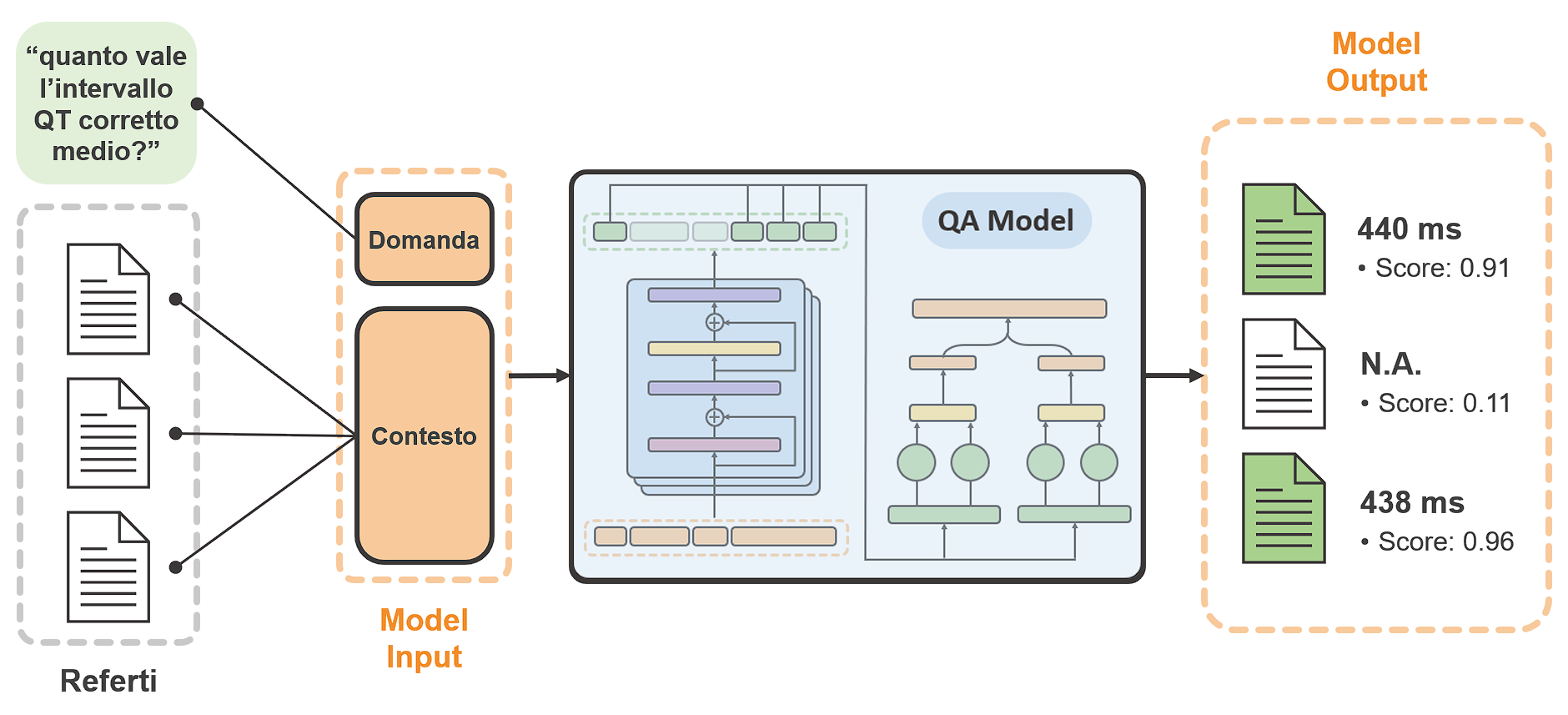
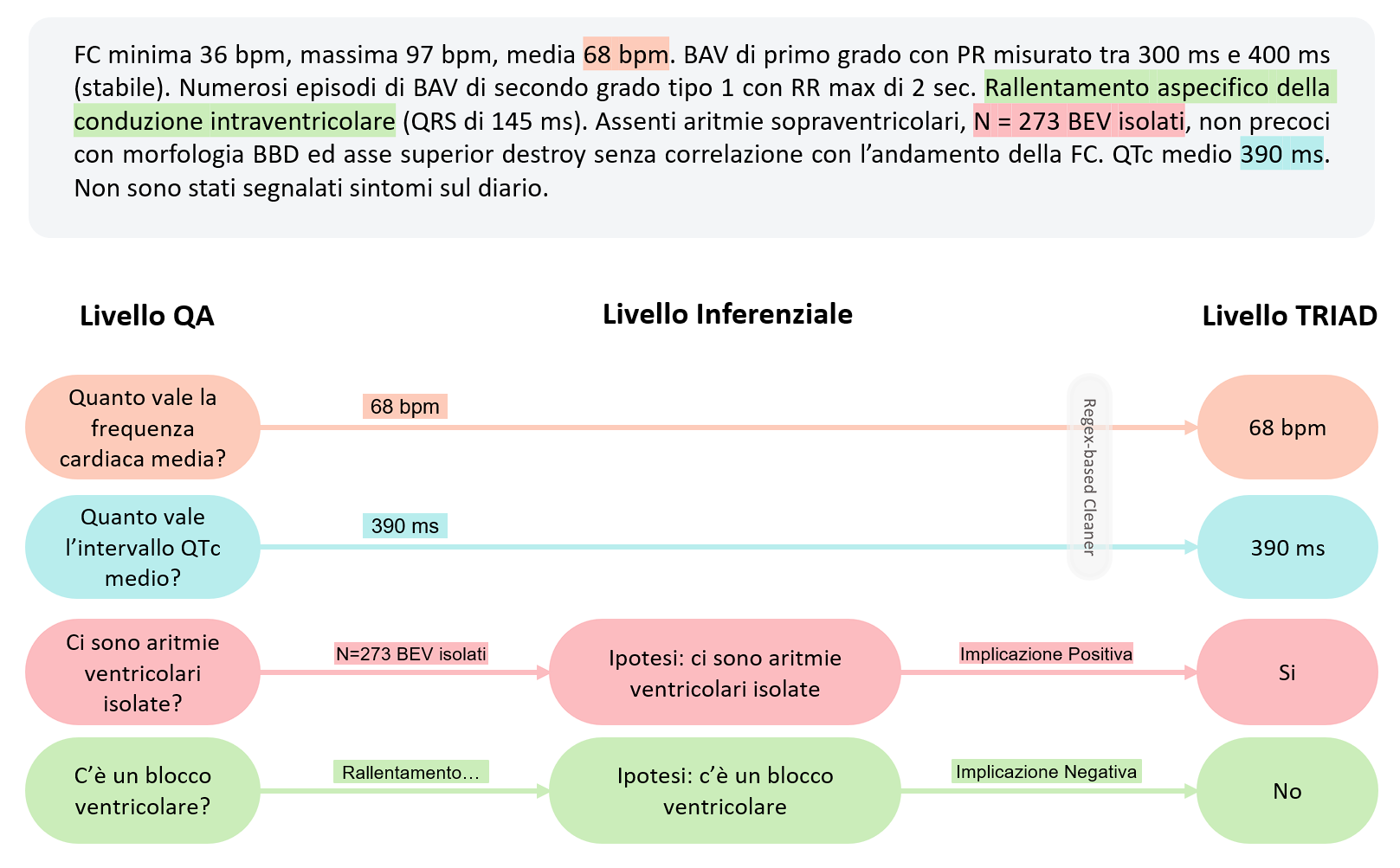
Nella seconda fase del nostro esperimento abbiamo dunque implementato un modello di QA basato su BERT per popolare automaticamente TRIAD, un database in cui vengono raccolte (manualmente) le informazioni dei referti di Cardiologia molecolare. Concentrandoci inizialmente sulla sezione Holter ECG, ci si è posti l’obiettivo di compilare cinque campi di tipo numerico, categorico e binario. I risultati mostrano un’elevata aderenza (prossima al 90%) fra le risposte del modello e le annotazioni, soprattutto per i campi numerici. La compilazione dei campi binari e categorici, invece, porta alla luce una questione rilevante nel processo di conversione dell’informazione grezza in dati strutturati: la necessità di effettuare inferenza basata su estrazione ed estrapolazione. In qualunque modo si configuri il problema, infatti, gli approcci di apprendimento supervisionato basati su testi annotati estraggono informazione, non la estrapolano. Ad esempio, la risposta “rallentamento aspecifico della conduzione intraventricolare” che il modello è in grado di estrarre dal referto non consente di compilare direttamente il corrispondente campo binario relativo alla presenza di blocchi ventricolari, rendendo necessario un passo intermedio di interpretazione manuale, come illustrato in Figura 3.
Conclusioni
Il nostro esperimento dimostra come i recenti progressi del NLP abbiano permesso di ridurre sostanzialmente il divario fra AI e pratica clinica rendendo possibile: interrogare rapidamente numerosi referti testuali senza doverli leggere; facilitare la compilazione di registri e database; identificare concetti clinici con precisione. Restano tuttavia ancora aperte alcune questioni importanti, come l’integrazione nel sistema del processo inferenziale necessario ad interpretare le risposte in accordo con le opzioni limitate previste da registri e database: una sfida per il futuro che non deve assolutamente scoraggiare, in quanto l’AI possiede metodologie e tecnologie per la rappresentazione della conoscenza in forma informatizzata e per il ragionamento automatico da cui poter attingere per progredire in questo settore. Materiale supplementare.
